Questions? Please join us on Slack, email us and check out the FAQ.
We hold office hours on Slack every Thursday 9am CST. Please join us on and say hi! in #general. Specific questions can be asked in the #developers, #extractors and #deployments channels.
Clowder is a cloud native data management framework to support any research domain. Clowder was developed to help researchers and scientists in data intensive domains manage raw data, complex metadata, and automatic data pipelines.
Clowder is not a central system, but software that research labs and individual users can install on local clusters or in the cloud. Clowder is data agnostic, but can be customized for specific data types through a sophisticated information extraction bus and web based visualization plugins.
Clowder is also a community of practitioners working on data intensive research projects and developing tools that work across research domains.
The first version of Clowder (v1) has been in development for over ten years and it has been used in various domains. A new version of Clowder, v2 is currently in development. v2 builds on lessons learned from current and prior use cases and is being developed with two major goals in mind:
- a modernized web interface for end users
- an easy to pickup and easy to maintain codebase
We are always looking for new collaborators, contributors, and ideas in the space of research data management.
- If you are interested in contributing to Clowder v2 please come say hi in Slack
- If you are ready to dive into the code, take a look at good first issues in v2
- If you have a project where Clowder could be of help but you are not sure, Slack is a also a great place to share your needs
Flexible Metadata Representation
Support for both user-defined and machine-defined metadata. System accepts metadata in a flexible representation based on JSON-LD. Users can add metadata entries directly from the UI. Extractors and external clients can attach metadata to files and datasets using the Web service API.
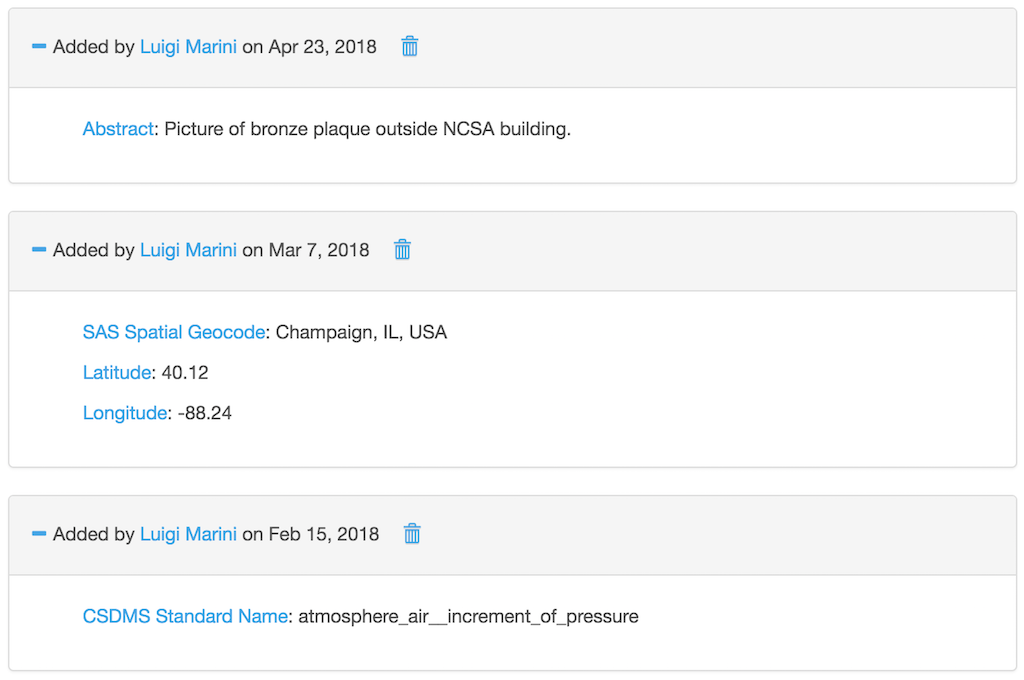 Human readable metadata.
Human readable metadata.
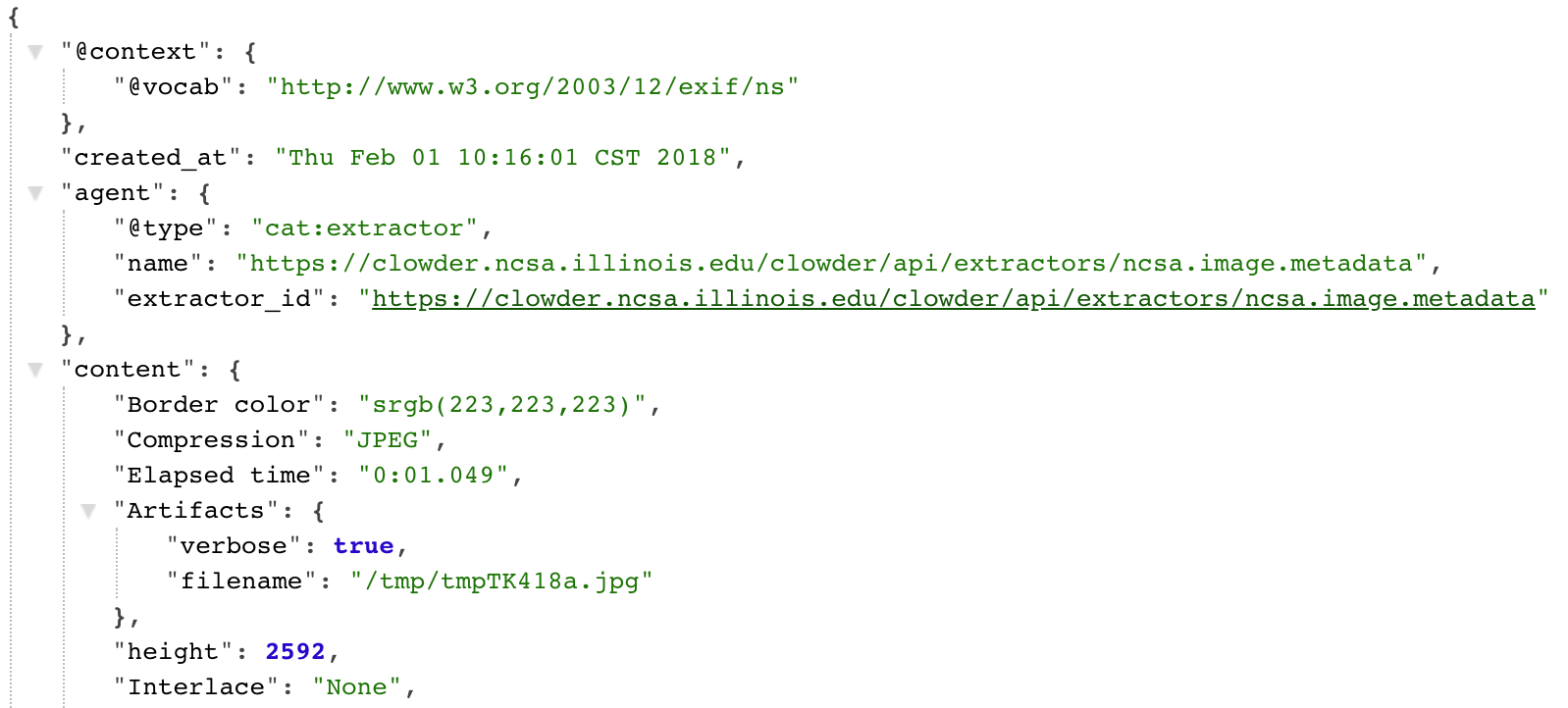 Machine parsable metadata.
Machine parsable metadata.
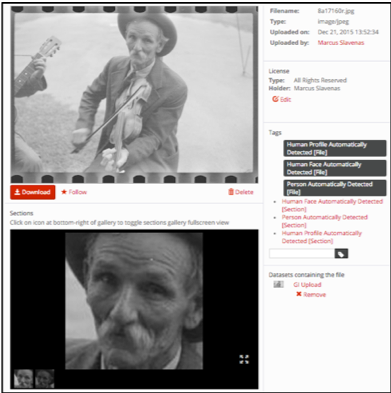
Automatic Metadata Extraction
When new data is added to the system, whether it is via the web front-end or through its Web service API, a cluster of extraction services process the data to extract interesting metadata and create web based data visualizations.
Extend the system by creating new extractors to analyze data. Using the publish-subscribe model and the RabbitMQ broker, when certain events occur in Clowder, such as the uploading of a new file, a message is published notifying any listening metadata extractors that a new file is available. Each extractor can then use the public Web Service API to analize the data and write back to Clowder any relevant information.
A partial list of available extractors is available on GitHub, in the NCSA Bitbucket and in the wiki.
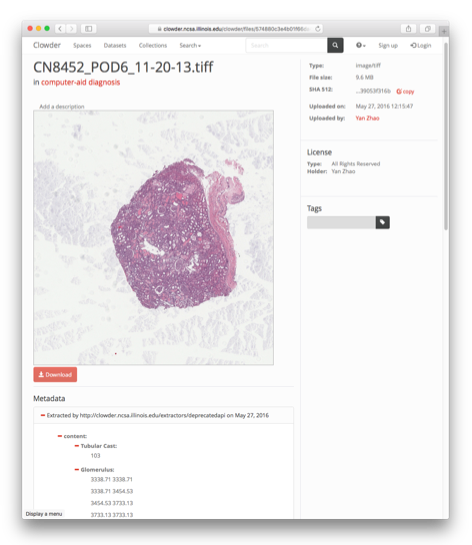
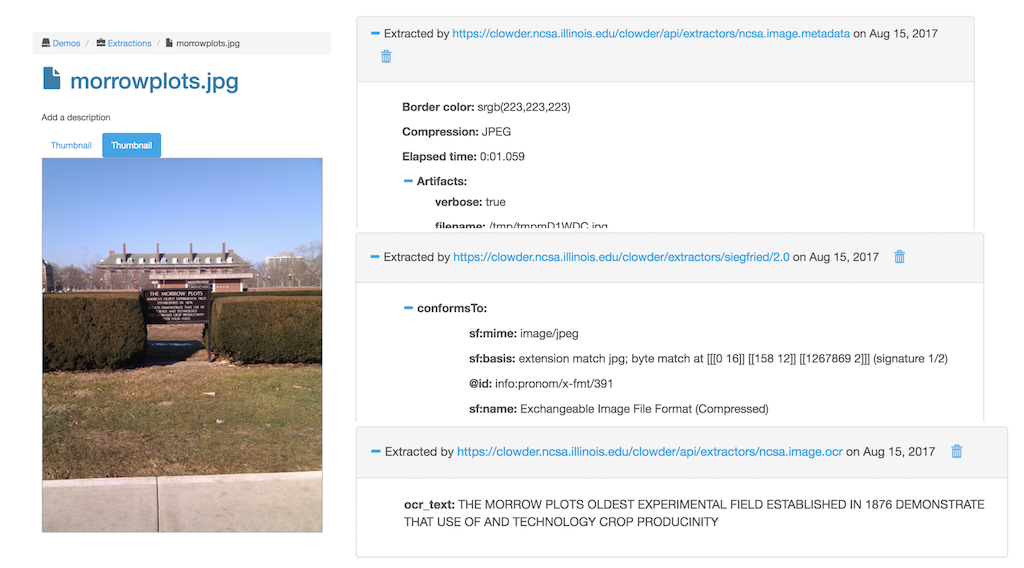 Metadata about the image automatically extracted by cloud metadata extractors.
Metadata about the image automatically extracted by cloud metadata extractors.
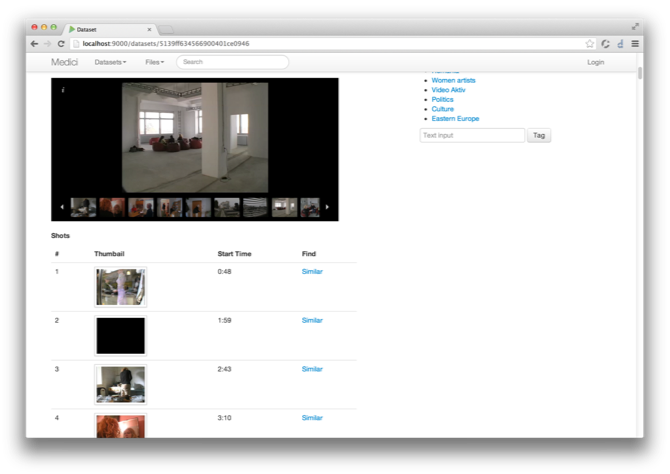
Data Visualizations
To preview the content of large files and visualize the information contained in files and datasets in a meaningful way, Clowder provides ways to write Javascript based widgets that can be added to files and datasets. Often these data previews are added by automatic extractions.
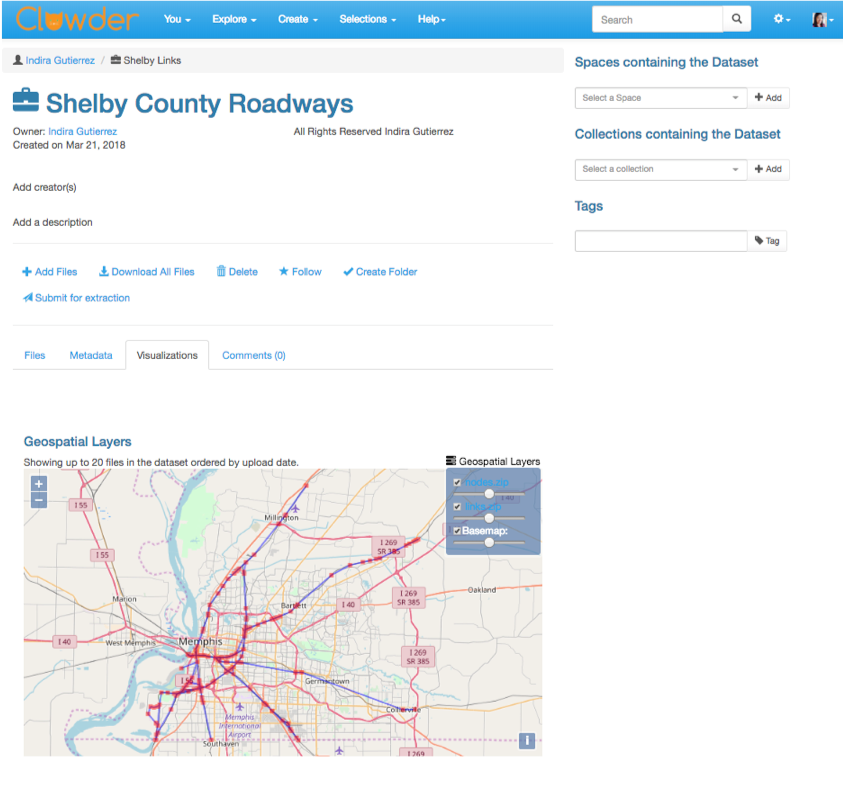
For example, the geospatial extractors watch for shapefiles and geotiff files to be uploaded to Clowder and then submit the GIS layers to an instance of Geoserver. A custom Javascript previewer visualizes the data on an interactive map.